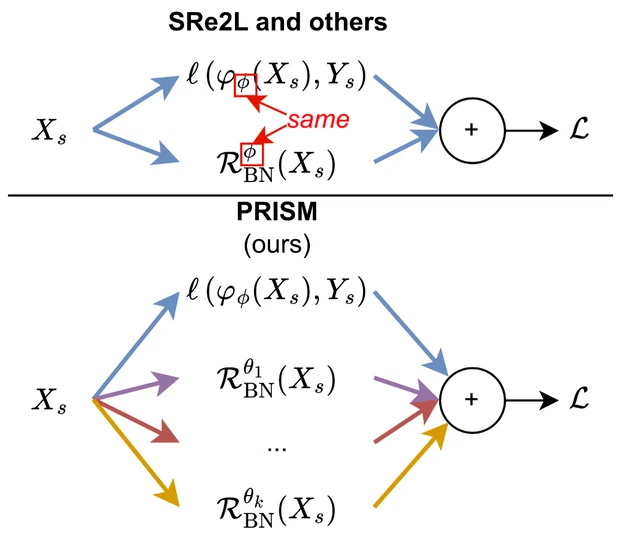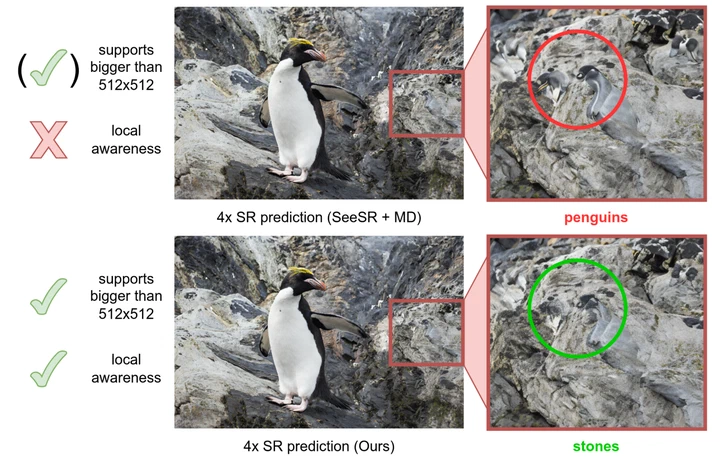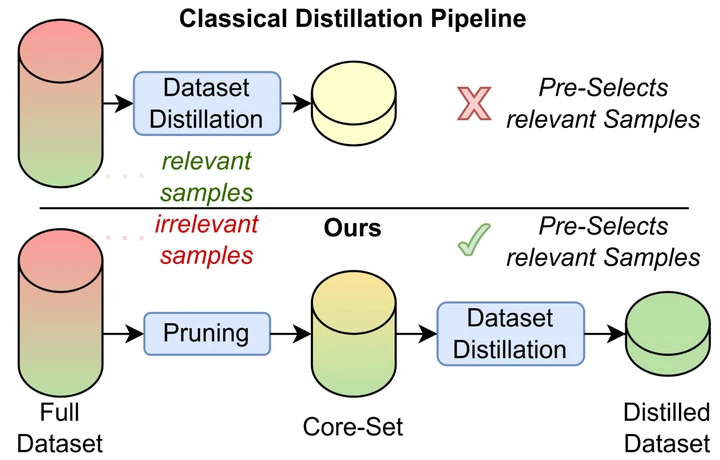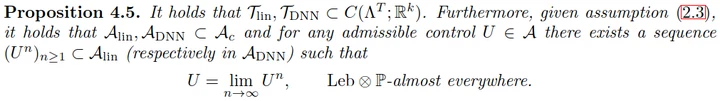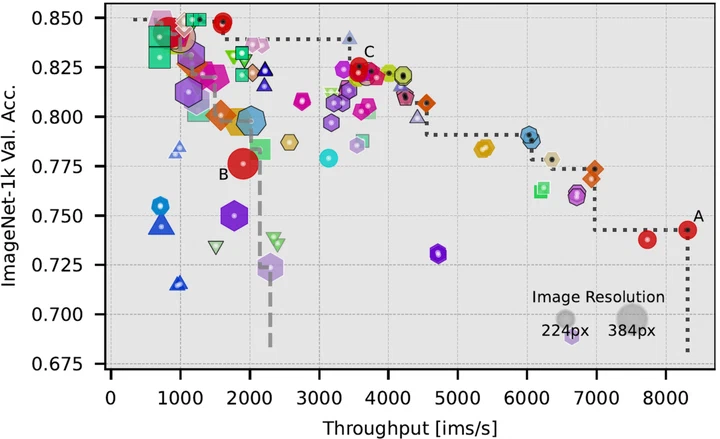
LUMA: Benchmarking Segmentation via a Lightweight Universal Mask Adapter
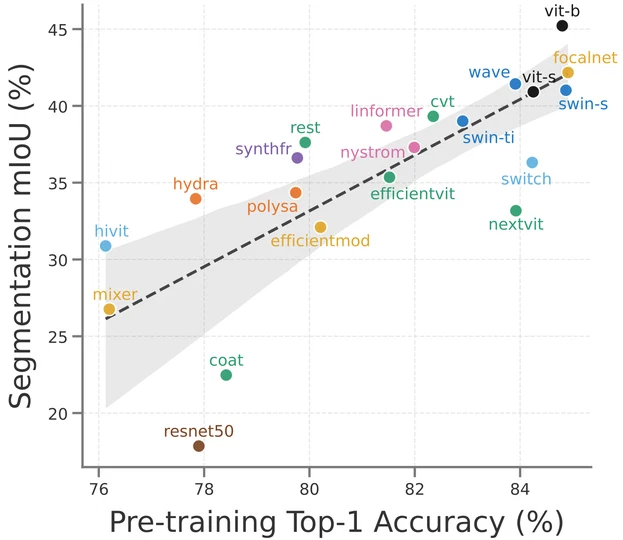
LUMA is a lightweight, backbone-agnostic mask-transformer head that lets us fairly compare segmentation backbones by fixing the decoder. Benchmarking 20 backbones and 11 pretraining schemes, we find that “efficient” token mixers don’t actually deliver efficiency and that the pretraining objective, not the architecture, governs segmentation quality.