Abstract
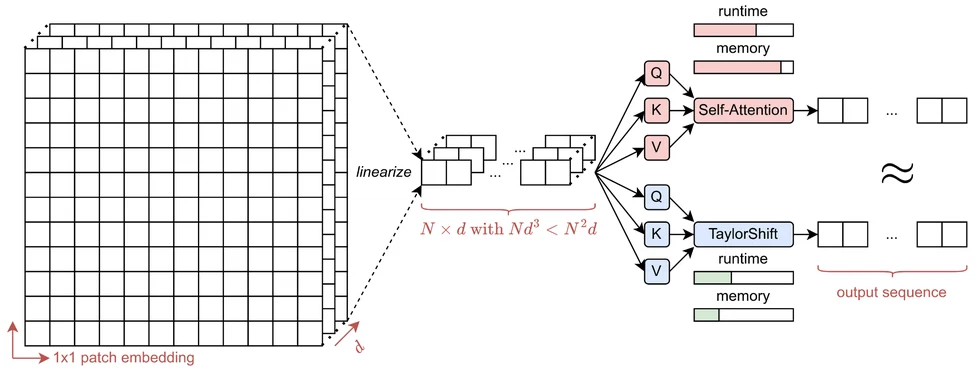
Transformer-based Super-Resolution (SR) models have recently advanced image reconstruction quality, yet challenges remain due to computational complexity and an over-reliance on large patch sizes, which constrain fine-grained detail enhancement. In this work, we propose TaylorIR to address these limitations by utilizing a patch size of 1x1, enabling pixel-level processing in any transformer-based SR model. To address the significant computational demands under the traditional self-attention mechanism, we employ the TaylorShift attention mechanism, a memory-efficient alternative based on Taylor series expansion, achieving full token-to-token interactions with linear complexity. Experimental results demonstrate that our approach achieves new state-of-the-art SR performance while reducing memory consumption by up to 60% compared to traditional self-attention-based transformers.
This work builds on the TaylorShift attention mechanism.
For more information, see the paper pdf.
Citation
If you use this work, please cite our paper:
@misc{nagaraju2024lowresolutionimageworth1x1,
title = {A Low-Resolution Image is Worth 1x1 Words: Enabling Fine Image
Super-Resolution with Transformers and TaylorShift},
author = {Sanath Budakegowdanadoddi Nagaraju and Brian Bernhard Moser and
Tobias Christian Nauen and Stanislav Frolov and Federico Raue and
Andreas Dengel},
year = {2024},
eprint = {2411.10231},
archiveprefix = {arXiv},
primaryclass = {cs.CV},
note = {Accepted to ICPR 2026},
}
