Abstract
Comparing transformer backbones for image segmentation is confounded: each is paired with a different decoder, recipe, and pretraining, so reported differences rarely reflect the backbone itself. We introduce the Lightweight Universal Mask Adapter (LUMA), a lightweight, backbone-agnostic mask-transformer head that treats any backbone as a black-box feature extractor, letting a set of queries read from its features through cheap cross-attention. LUMA matches the accuracy of EoMT, the state-of-the-art efficient ViT-segmenter, at lower cost, while attaching unchanged to isotropic, hierarchical, convolutional, and mixture-of-experts backbones alike. Holding this head fixed, we benchmark 20 backbones, 11 pretraining schemes and a range of resolutions on ADE20K and Cityscapes under one modern recipe. We find that ``efficient’’ token mixers fail to deliver efficiency even at the high resolutions that motivate them, with plain ViT holding the throughput Pareto-front at every resolution. Additionally, the pretraining objective, not the architecture, the lever the field has tuned hardest, governs segmentation quality.
For the full details, see the paper pdf.
The Problem: Backbone Comparisons Aren’t Fair
Which transformer backbone is best for image segmentation? The honest answer is that we don’t know — because we’ve never compared them fairly. Every backbone ships with its own decoder, training recipe, pretraining scheme, and input resolution. When two segmenters differ, we can’t tell whether the backbone did it or the apparatus bolted around it did.
The state-of-the-art lightweight ViT segmentation head, EoMT, is a case in point. It fuses the segmentation queries into the backbone’s attention, which buys efficiency but hard-codes three assumptions: global attention, reach-in access to block internals, and a constant token width. That is fine for a plain ViT — and disqualifying for everything else. You cannot use EoMT to benchmark a hierarchical, convolutional, or mixture-of-experts backbone, because those backbones violate its assumptions.
To compare backbones, we first need a decoder that treats every backbone the same.
LUMA: One Head for Every Backbone
LUMA (Lightweight Universal Mask Adapter) is a mask-transformer head that treats any backbone as a black-box feature extractor. Instead of injecting queries into the backbone’s attention, LUMA keeps them in a separate side stream running alongside the patch tokens.
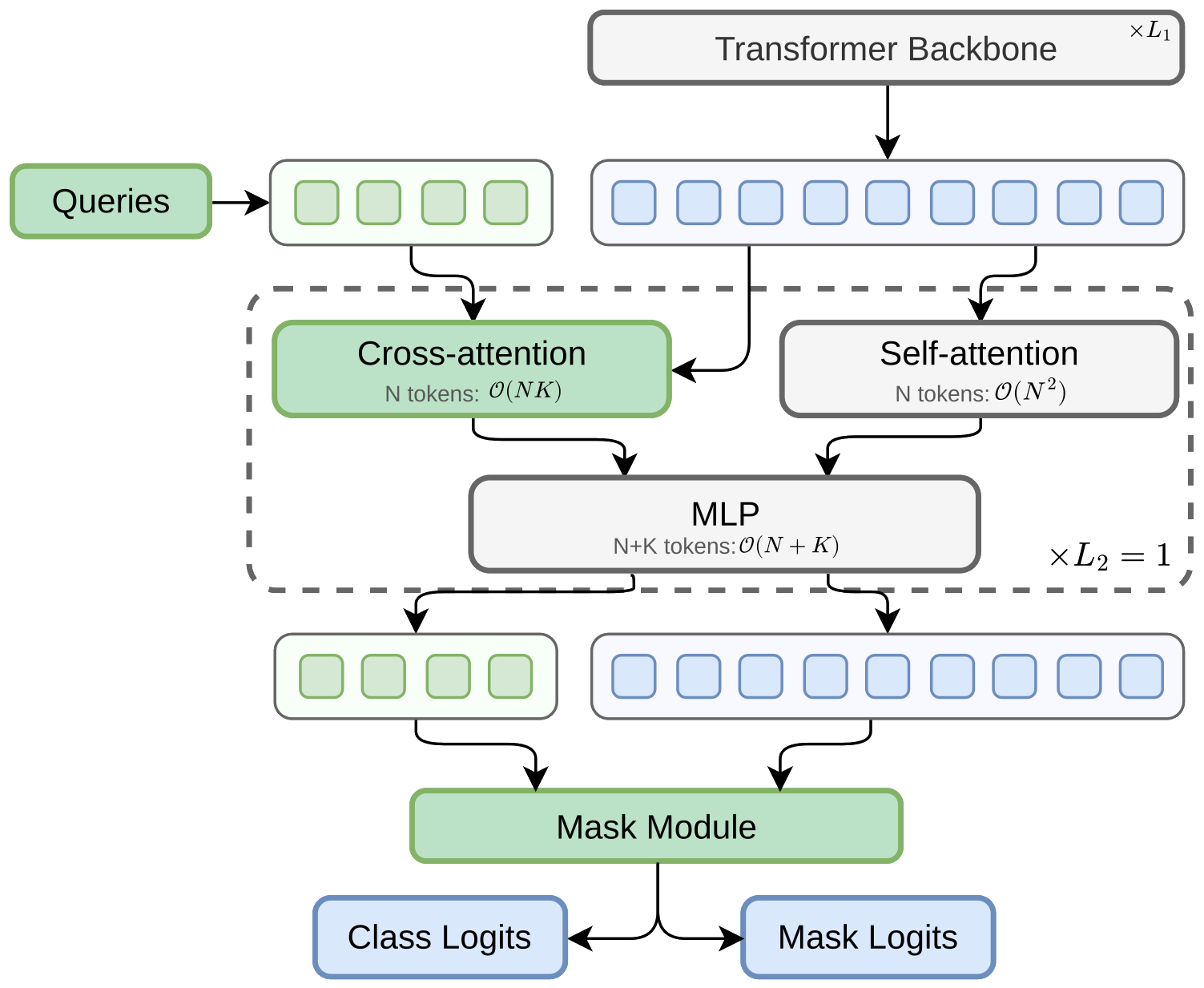
At each tapped backbone block $i$, the queries do two things:
- Read the current patch features $X_i$ through a single cross-attention layer; the only place queries and tokens interact.
- Reuse the backbone’s own feed-forward layers, so the queries automatically inherit its width schedule and any dimension changes.
Because the queries never enter the backbone’s token mixer, all three of EoMT’s constraints disappear: no global attention needed, no access to internals, no constant-width assumption. The same head attaches, unchanged, to isotropic, hierarchical, convolutional, and MoE backbones alike.
Two further simplifications fall out of this design:
- No masked attention. Plain cross-attention matches the accuracy of EoMT’s masked-and-annealed formulation during training, so LUMA drops the intermediate mask predictions and the annealing schedule entirely.
- Cheaper attention. Keeping queries external turns the per-block cost from $\mathcal{O}((N+K)^2)$ into $\mathcal{O}(N^2 + NK)$ for $N$ patch tokens and $K$ queries, and uses only a single tapped block $(L_2 = 1)$ against EoMT’s $L_2 = 4$.
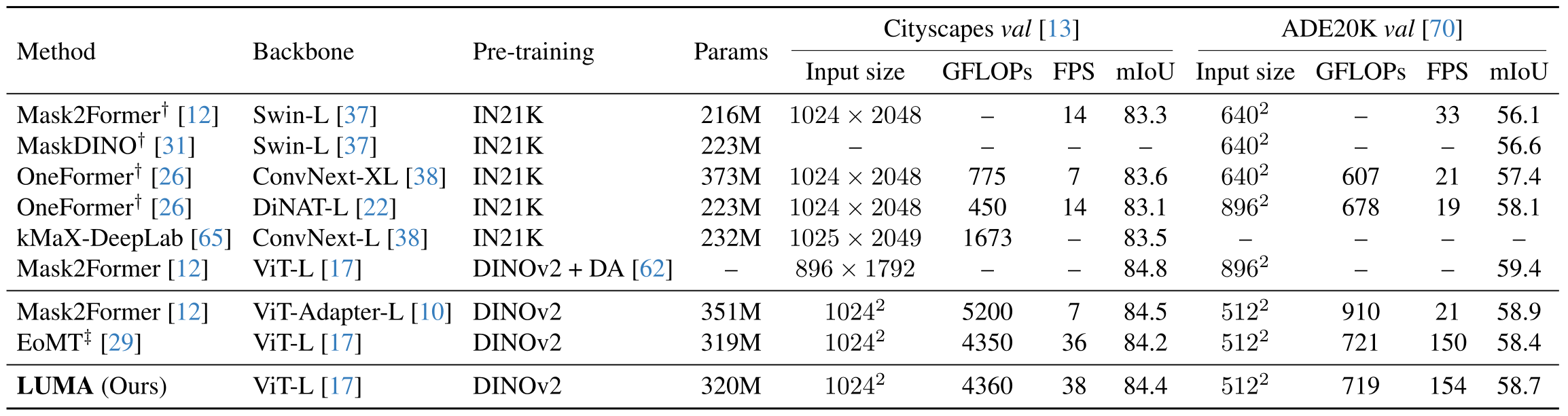
The payoff is that LUMA matches EoMT, while working with any backbone. This makes LUMA a fair measuring instrument, not just another segmenter.
The Benchmark
With the head held fixed, everything else becomes a controlled variable. We benchmark under one modern recipe:
- 20 backbones spanning isotropic ViTs, hierarchical, convolutional, and mixture-of-experts designs.
- 11 pretraining schemes, from supervised to dense and self-supervised objectives (MAE, DINO, EVA-02, CLIP, SAM, JEPA).
- Two datasets, ADE20K and Cityscapes, across a range of resolutions (224 – 1024 px).
- Measured on mIoU, throughput, inference memory, and GFLOPs, analyzed on the Pareto front.
What We Found
“Efficient” token mixers aren’t efficient
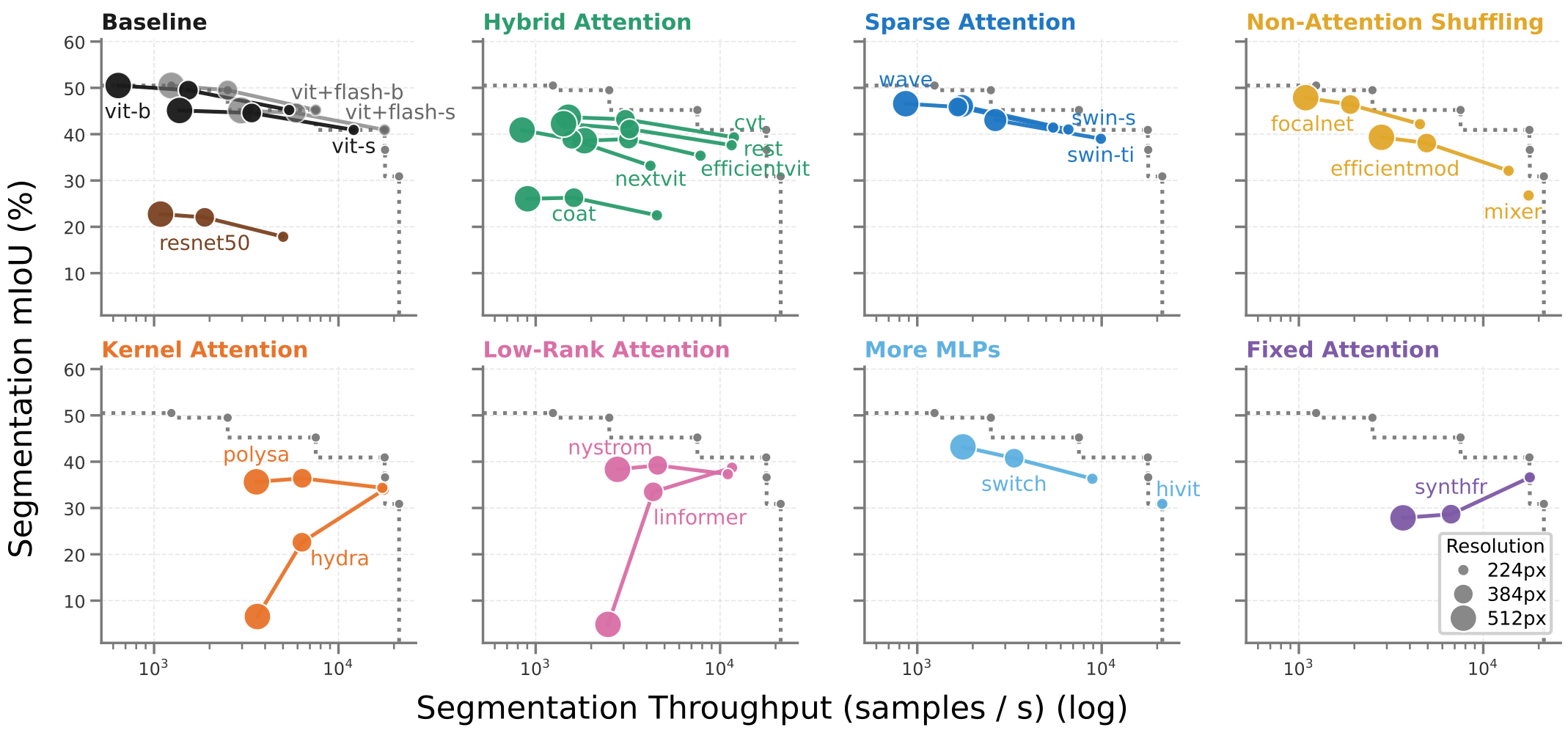
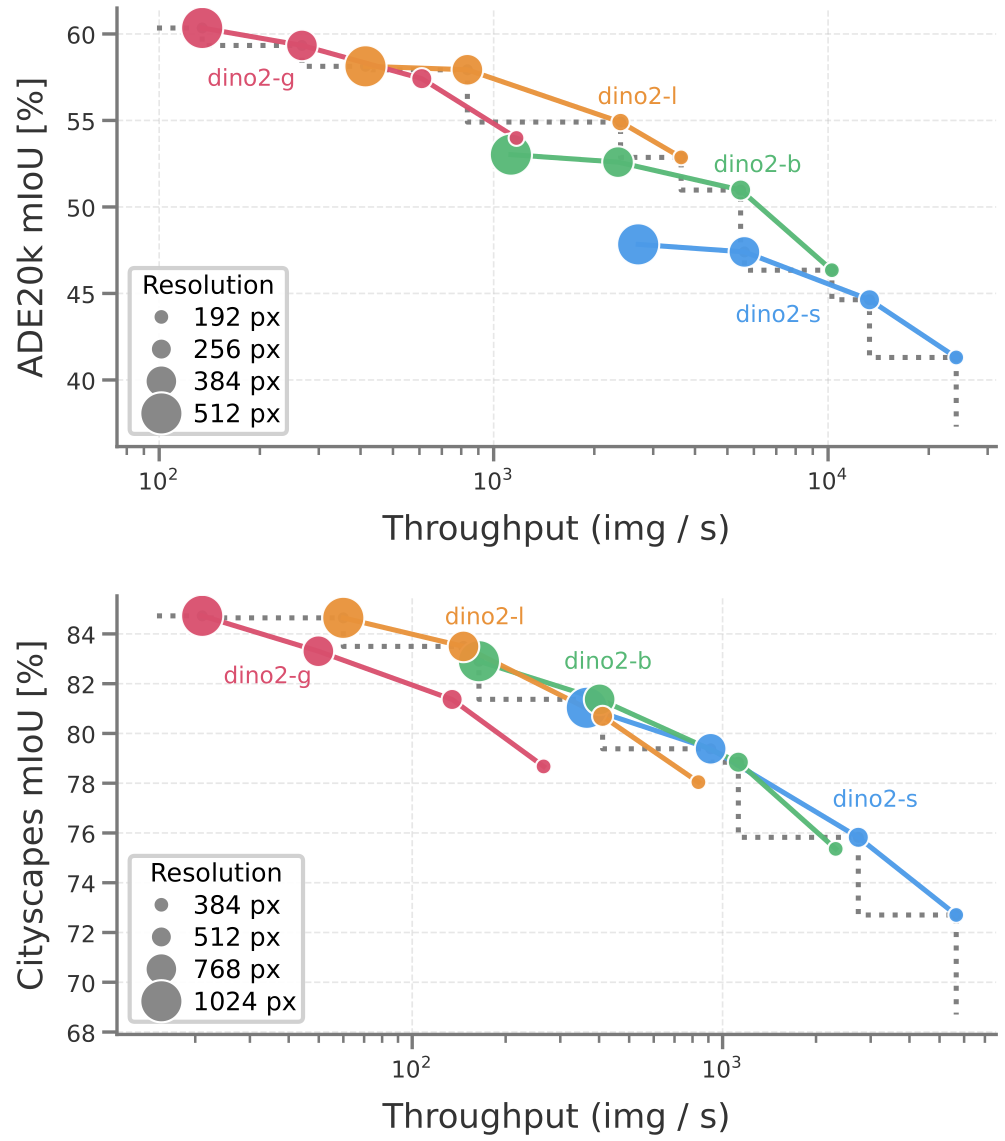
The whole premise of efficient token mixers is that they pay off at high resolution, where the sequence gets long. Segmentation is exactly that regime and still, plain ViT holds the throughput Pareto-front at every resolution (even without FlashAttention). The “efficient” variants are competitive only on memory. Worse, several sequence-length-bound mixers fail catastrophically as resolution grows (Hydra, Linformer, Synthesizer).
Pretraining objective beats architecture
The lever the field has tuned hardest, the token mixer, turns out to be a weak one. The strong lever is how the backbone was pretrained.
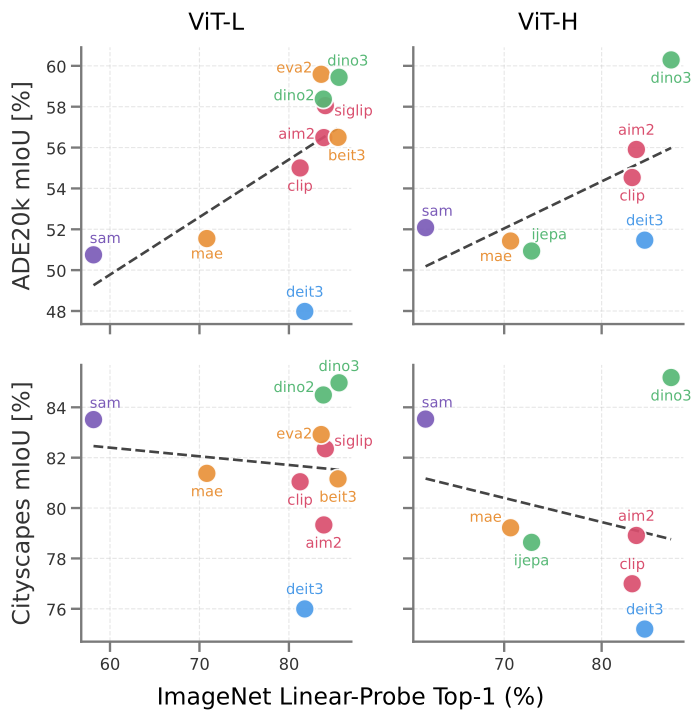
Dense objectives (masked image modeling, DINO-style self-distillation) transfer robustly, while supervised training is an outlier, sitting roughly 8 percentage points below the accuracy-vs-mIoU trend, and EVA-02 reaches 59.7 mIoU on ADE20K despite only mid-pack ImageNet accuracy. In our experiments, the best pretraining objectives are DINOv3 and EVA-02.
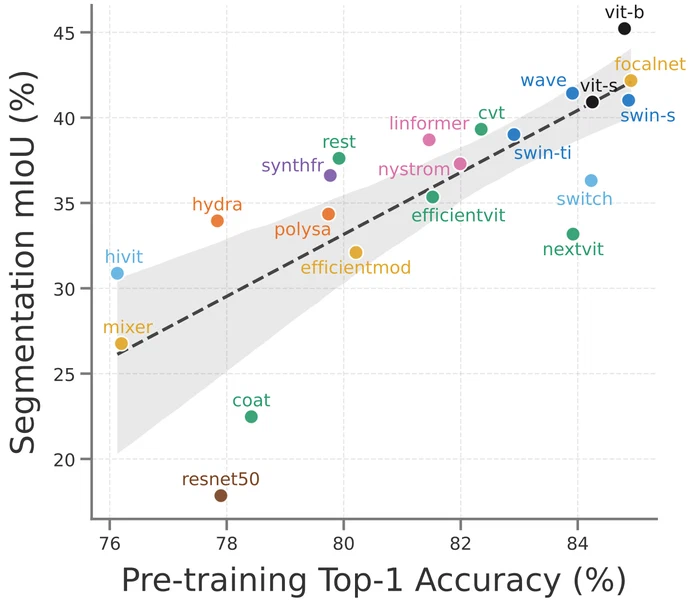
ImageNet accuracy doesn’t predict segmentation
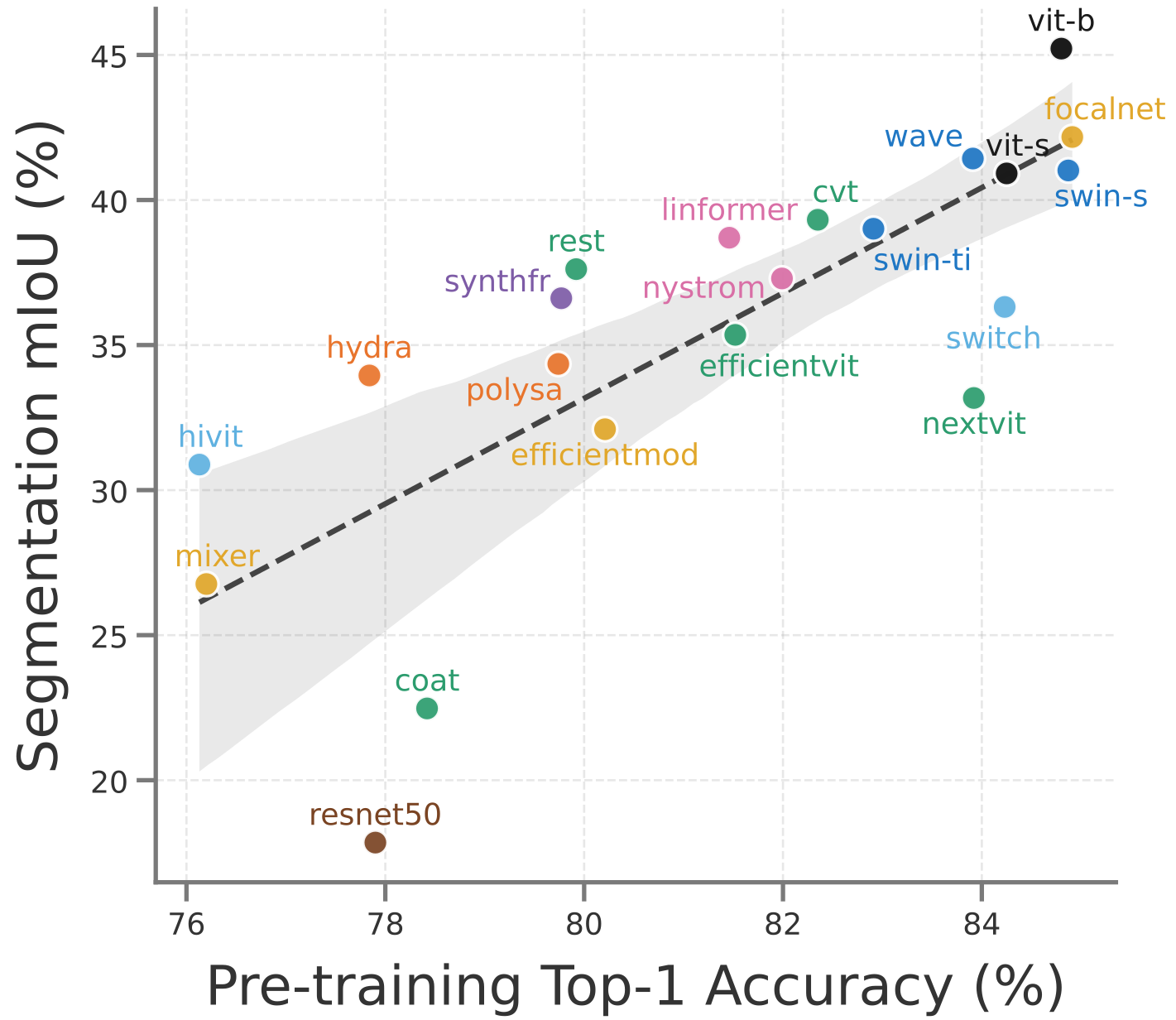
If you pick backbones by their ImageNet top-1, you’re rolling dice. Correlation between classification accuracy and segmentation mIoU (both at 224 px resolution) is moderate ($r \approx 0.78$ on ADE20K and $r \approx 0.71$ on Cityscapes), but with significant outliers. For example, ViT-B, Next-ViT, and CoaT. For different pretraining objectives, this becomes even worse with low correlation on ADE20K (driven mostly by outliers) to even negative correlation on Cityscapes.
Spend compute on size, not resolution
Fitting power laws across model sizes and resolutions gives a clean compute-optimal rule: Roughly 80% of added compute should go to model size $(N^* \propto C^{0.83})$ and only 20% to additional image tokens $(T^* \propto C^{0.2})$, i.e. to higher resolution.
TL;DR: How to Pick a Backbone
The benchmark points to a simple, almost boring recipe, which is precisely the finding:
- Keep a simple architecture. Plain ViT remains the backbone of choice and is most efficient with FlashAttention, even for large images.
- Initialize from a dense-objective foundation model, not a supervised checkpoint. We recommend DINOv3 or EVA-02.
- Spend added compute on model size before resolution, following a rough 80/20 split.
The community’s effort is best aimed not at new token mixers, but at pretraining objectives and scalable architectures, measured fairly on the dense task itself.
Citation
If you use this work, please cite our paper:
@misc{nauen2026luma,
title = {LUMA: Benchmarking Segmentation via a Lightweight Universal Mask
Adapter},
author = {Tobias Christian Nauen and Anosh Billimoria and Federico Raue and
Stanislav Frolov and Brian Moser and Andreas Dengel},
year = {2026},
eprint = {2607.00687},
archiveprefix = {arXiv},
primaryclass = {cs.CV},
}
