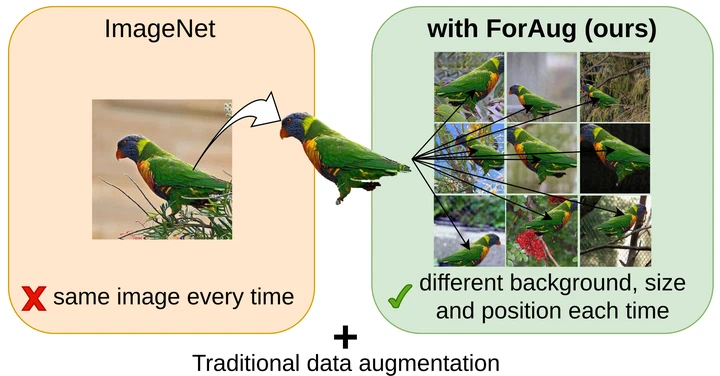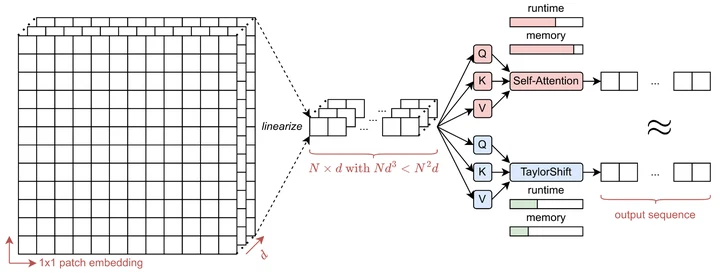
The Gentle Collapse: Distributional Metrics for Continual Learning
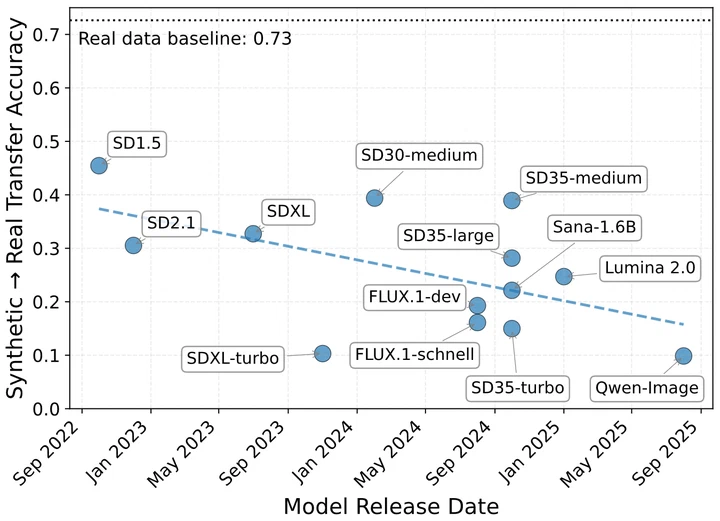
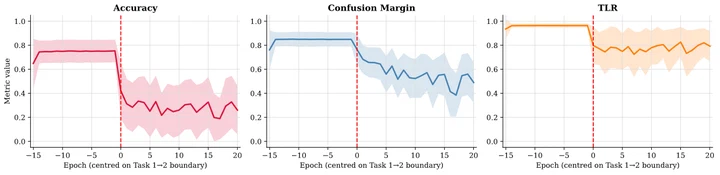
Accuracy alone hides how models forget in continual learning. We introduce six softmax-derived metrics covering rank, confidence, and distributional divergence that expose class-level forgetting patterns invisible to accuracy. Using these as loss weights or replay sampling criteria reduces forgetting by up to 7.7 pp on TinyImageNet over uniform experience replay.