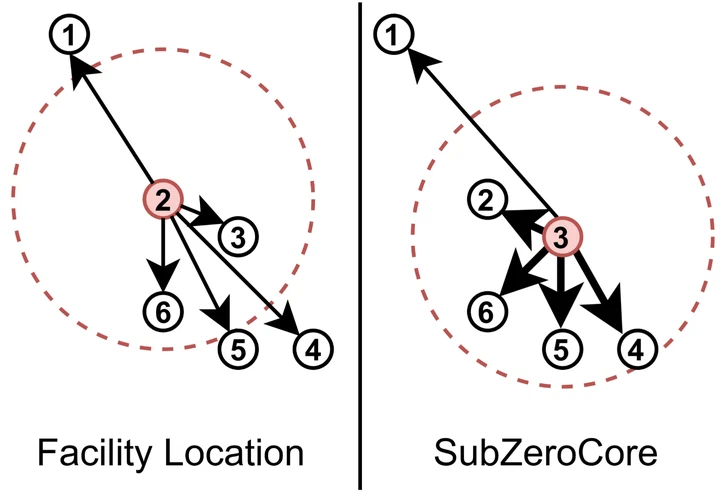
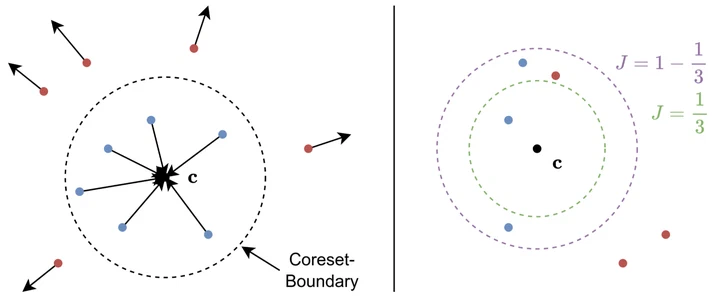
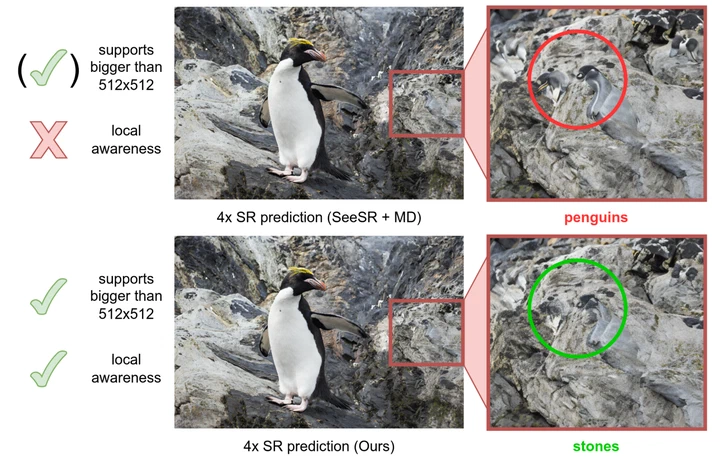
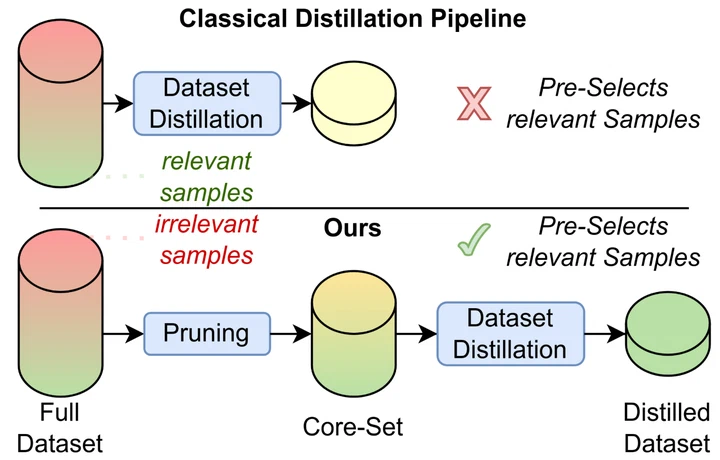
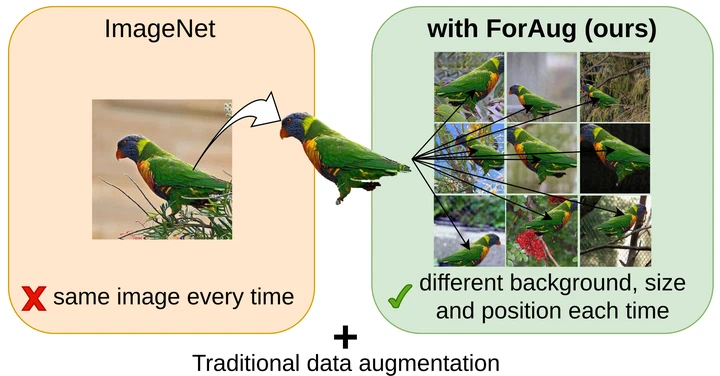
OA-CutMix: Correcting the Label Bias of CutMix
CutMix assigns labels by patch area, not by visible object content, a systematic bias that mislabels 21.5% of samples and creates ghost labels in 17%. OA-CutMix replaces the label with one derived from object area, leaving the image mixing unchanged. It matches or beats 10+ static and dynamic mixing methods across 4 architectures and 6 datasets.